
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- 자바스크립트 객체
- 자바스크립트
- 네이버 부캠
- 자바스크립트 컴파일
- 네이버 부스트캠프 멤버십
- 파이썬
- Next/Image 캐싱
- c++
- PubSub 패턴
- 프로그래머스
- beautifulsoup
- Next.js
- Image 컴포넌트
- react
- 자바 프로젝트
- 브라우저 동작
- 부스트캠프
- React.js
- 멘션 추천 기능
- 코딩테스트
- React ssr
- 파이썬 코딩테스트
- 씨쁠쁠
- 스택
- 비디오 스트리밍
- 파이썬 웹크롤링
- git checkout
- Server Side Rendering
- 웹크롤링
- 네이버 부스트캠프
- Today
- Total
코린이의 개발 일지
[파이썬 웹크롤링] - 웹페이지 텍스트 내용 가져오기 (BeautifulSoup 사용) 본문
안녕하세요 폴라민입니다.
오늘은 BeautifulSoup을 사용해서 간단한 텍스트 정보를 가져와 보려고 합니다.
BeautifulSoup은 웹페이지 텍스트를 가져오는데 아주 유용한 파이썬 라이브러리 입니다.
우선 간단한 예제를 한번 볼까요?

제 블로그 다른 포스팅 웹 페이지 인데요. 여기서 상단에 글 제목을 가져와 볼겁니다.
우선 가져오기 위해서는 페이지 정보를 알아야하는데
윈도우 크롬 기준을 F12를 누르면 개발자 도구가 뜹니다.

이런식으로 떴을 때, 저기 하트 보이시나요? 하트 오른쪽에 화살표를 누르시면

이런식을 마우스로 가리키면 그 부분의 html 태그가 뜹니다. 저희는 이 태그를 활용해서 글 제목을 가져올겁니다.
아래 코드를 볼까요?
import requests
from bs4 import BeautifulSoup
res=requests.get('https://polarmin.tistory.com/29') # 웹페이지 가져오기.
soup=BeautifulSoup(res.content,'html.parser') #웹페이지 파싱하기.
data=soup.find('div',class_="hgroup")
# data=soup.find('div',"hgroup")
# data=soup.find('div',attrs={'class': "hgroup"})
title=data.find('h1')
print(title.get_text())위의 코드를 보면 우선 requests 모듈을 활용해 웹페이지를 가져옵니다.
그리고 가져온 정보를 BeautifulSoup을 활용하여 데이터 처리를 해준다고 보시면 됩니다.
soup이라는 변수에 BeautifulSoup 객체를 담고 이 Soup의 메소드 find를 활용하여 <div> 태그 중에서 class : hgroup 인 데이터를 가져옵니다.
밑에 주석 처리된 부분은 세 문장이 모두 같은 기능을 하는 문장들 입니다. 세개의 방법 중에 본인이 편한 방법을 사용하시면 됩니다.
data=soup.find('div',class_="hgroup") -> 이 방법을 쓰실 때, class 뒤에 반드시 _ 를 붙여주는 거에 유념해 주세요!!
data=soup.find('div',"hgroup")
data=soup.find('div',attrs={'class': "hgroup"})

자 div class="hgroup" 까지 찾았으니 이제 찾은 부분에서 h1 태그를 찾아야 겠죠?
data=soup.find('div',class_="hgroup")
title=data.find('h1')
주의해 주세요!! 밑에 문장은 soup.find가 아니라 data.find 입니다.
우리가 div 태그까지 찾아서 data라는 변수에 객체를 담았으니 다시 그 객체 안에서 h1태그를 찾는 작업을 하는 겁니다.
자 이제 찾는 작업은 다 했으니 문자 내용만 추출해오면 됩니다.
그건 어렵지 않아요
print(title.get_text())
위와 같이 get_text() 메소드를 사용하면 됩니다.
그러면 출력결과가 아래와 같이 나옵니다.
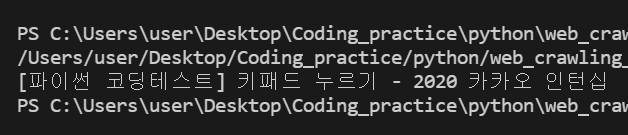
이렇게 간단하게 텍스트 내용을 가져와 봤습니다.
이를 응용하면 더 복잡한 내용도 가져올 수 있겠죠?
다음 포스팅에서 더 재밌는 내용을 크롤링해와 봅시다.
다음 포스팅에서 봐요~~ 안녕!
'프로젝트 > 콘솔 프로그램' 카테고리의 다른 글
| [자바] 콘솔로 간단한 보드게임 만들기 - 구현편 (0) | 2022.06.19 |
|---|---|
| [자바] 콘솔로 간단한 보드게임 만들기 - 설계편 (0) | 2022.06.13 |
| [파이썬 미로 그리기] 텍스트 파일 읽어와서 이중리스트에 담기 (0) | 2022.03.13 |
| [파이썬 웹크롤링] 파이썬으로 네이버 웹툰 목록 가져와서 별점순 정렬하기 (BeautifulSoup) (1) | 2022.01.24 |
| [파이썬 웹크롤링] 파이썬으로 네이버 웹툰 제목 목록 가져오기 - BeautifulSoup 사용 (0) | 2022.01.23 |


